Are you a Quiet Speculation member?
If not, now is a perfect time to join up! Our powerful tools, breaking-news analysis, and exclusive Discord channel will make sure you stay up to date and ahead of the curve.
And now it's time for everyone's favorite part of the banlist test: the experimental data. With 500 matches of Jund with and without Punishing Fire under my belt, I have developed a very strong opinion on unbanning the card. Today, I will reveal the hard numbers and their statistical significance. As always, these data are meant to explore the impact of the tested card, but I can't test every single impact, metagame shift, or other permutation that could arise.

If you're just joining us, be sure to first read the Experimental Setup for this project.
Boilerplate Disclaimers
Contained are the results from my experiment. It is entirely possible that repetition will yield different results. This project models the effect that the banned card would have on the metagame as it stood when the experiment began. My result does not seek to be definitive, but rather provide a starting point for discussions on whether the card should be unbanned.
Meaning of Significance
When I refer to statistical significance, I really mean probability; specifically, the probability that the differences between a set of results are the result of the trial, and not of normal variance. Statistical tests are used to evaluate whether normal variance is behind the result, or if the experiment caused a noticeable change in result. This is expressed in confidence intervals determined by the p-value from the statistical test. In other words, statistical testing determines how confident researchers are that their results came from the test and not from chance. The assumption is typically "no change," or a null hypothesis of H=0.
 If a test yields p > .01, the test is not significant, as we are less than 90% certain that the result isn't variance. If p < .01, then the result is significant at the 90% level. This is considered weakly significant and insufficiently conclusive by most academic standards; however, it can be acceptable when the n-value of the data set is low. While significant results are possible as few as 30 entries, it takes huge disparities to produce significant results, so sometimes 90% confidence is all that is achievable.
If a test yields p > .01, the test is not significant, as we are less than 90% certain that the result isn't variance. If p < .01, then the result is significant at the 90% level. This is considered weakly significant and insufficiently conclusive by most academic standards; however, it can be acceptable when the n-value of the data set is low. While significant results are possible as few as 30 entries, it takes huge disparities to produce significant results, so sometimes 90% confidence is all that is achievable.
p < .05 is the 95% confidence interval, which is considered a significant result. It means that we are 95% certain that any variation in the data is the result of the experiment. Therefore, this is the threshold for accepting that the experiment is valid and models the real effect of the treatment on reality. Should p < .01, the result is significant at the 99% interval, which is as close to certainty as possible. When looking at the results, check the p-value to see if the data is significant.
Significance is highly dependent on the n-value of the data: in this case, how many games were recorded. The lower the n, the less likely it is that the result will be significant irrespective of the magnitude of the change. With an n of 30, a 10% change will be much less significant than that same change with n=1000. This is why the individual results frequently aren't significant, even when the overall result is very significant.
Overall Matchup Data
As a reminder and for those who've never seen one of these tests before, I played 500 total matches, with 250 per deck. I switched decks each match to level out any effect skill gains had on the data. Play/draw alternated each match, so both decks spent the same time on the draw and play. The test and control Jund lists can be found here.
As always, the overall match data comes first, and then I'll get into each matchup's results. Normally, I also include bonus data and interesting factoids, but I did record anything I thought was worth relating this time.
- Total Control Wins: 119 (47.6%)
- Total Test Wins: 127 (50.8%)
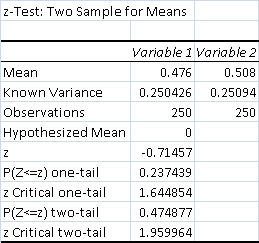
The data shows that adding Punishing Fire to Jund did not have a significant effect on its win percentage. p > .1 by a good margin, so the result is not even slightly significant. This means that the variation in the sample is most likely the result of normal variance and not my experiment.
I expected Punishing Fire to have a limited impact on Jund's win percentage because it is a very limited card. Far less efficient than Lightning Bolt, Fire is useful only because it is reusable. For that to be relevant, the game has to go long. The attraction has always been machine-gunning down opposing creatures, so I didn't expect there to be much effect outside of the creature matchups. Therefore, it would be on a deck-by-deck basis that the real impact became apparent. Of note, the smaller n-value for these results increases the threshold of significance.
Deck By Deck
Before getting into specifics, I have to note that actually testing the combo proved tricky, as there are two effects associated with playing Punishing Fire. The first: thanks to the aforementioned quirks of running the card, choices matter a lot more than previously. There was a lot of tension regarding which creature I pointed which kill spell at, as Fire is less mana-efficient than Lightning Bolt. My test deck had 2 Fatal Push, 3 Assassin's Trophy, and Liliana's downtick  to kill creatures with 3 or more power. This meant I had considerable incentive to avoid killing anything that might be Fireable, which led to some odd play patterns.
to kill creatures with 3 or more power. This meant I had considerable incentive to avoid killing anything that might be Fireable, which led to some odd play patterns.
The second: Punishing Fire is not a self-contained card. The only reason it has ever been threatening is Grove of the Burnwillows. Needing to run a full set of Groves puts some manageable strain on a deck's manabase, especially if that deck normally runs on fetches and shock lands. I compensated by running more black sources and no Stomping Ground.
What can't be compensated for is Grove giving opposing players life. While technically a positive since it triggers Fire (enabling the combo), if I didn't have Fire and needed the colored mana, the extra life quickly added up. When Tron was green/red and used Grove, the extra life didn't matter because Tron's creatures are huge. Jund's aren't so big, and in tight races that extra life might become a factor. Fortunately, it didn't come up too often.
UW Control
The UW versus Jund matchup is about attrition. Jund is designed to trade cards at value or better, while UW snows opponents under with card advantage. The matchup hinges on Jund sticking a threat that UW can't remove before that card advantage overcomes the attrition. Dark Confidant is Jund's best creature for this reason.
- Total Control Wins: 25 (50%)
- Total Test Wins: 33 (66%)
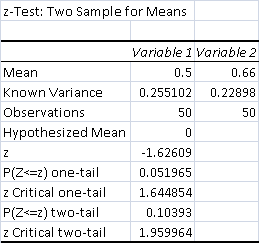
p > .05 by a very small margin. This means it's weakly significant. Because of the size of the data set, it would have taken one more test win or a control loss to make it absolutely significant.
 I wasn't expecting the UW matchup to improve, since it doesn't run many creatures. However, Fire meant that UW could never actually grind out Jund on card advantage, especially in game 1. As long as Jund had a Fire in its graveyard, it had a threat and an answer in one card. Instead, game one was about baiting UW to use a Field of Ruin on not-Grove. If that happened, UW could realistically never win, because Fire would eventually kill all its win conditions. Teferi cannot survive repeated turns of Fire, and if Jund found two Fires, which was guaranteed in a long game, then Celestial Colonnade and Jace, the Mind Sculptor are also doomed.
I wasn't expecting the UW matchup to improve, since it doesn't run many creatures. However, Fire meant that UW could never actually grind out Jund on card advantage, especially in game 1. As long as Jund had a Fire in its graveyard, it had a threat and an answer in one card. Instead, game one was about baiting UW to use a Field of Ruin on not-Grove. If that happened, UW could realistically never win, because Fire would eventually kill all its win conditions. Teferi cannot survive repeated turns of Fire, and if Jund found two Fires, which was guaranteed in a long game, then Celestial Colonnade and Jace, the Mind Sculptor are also doomed.
This meant it was never possible game one for UW to beat the test deck through Teferi loops and sitting back; it had to take the initiative. Jund won the games that went extremely long as a result. The sideboard games were a different story, since the sideboard creatures (especially Geist of Saint Traft) and Rest in Peace completely alter the matchup dynamic by reducing Fire's effectiveness.
Mono-Green Tron
Tron and Jund have the longest-standing predator/prey relationship in Modern. Jund's been struggling against Tron since the beginning of Modern, and while Jund's tools have gotten better, Tron has adapted to obviate them. Thoughtseize remains critical for Jund, which was bad news for the test deck.
- Total Control Wins: 24 (48%)
- Total Test Wins: 19 (38%)
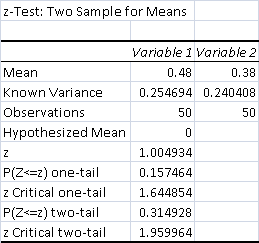
p > .1 means the results are not significant in any way, and are therefore not the result of the test.
Not surprisingly, incremental grinding over a long game was not very good against Tron. Fire never kills anything, and since it doesn't do as much damage as Bolt, it's not that useful racing, either. Also, Tron has Relic of Progenitus maindeck.
Bant Spirits
Spirits versus Jund is a strange matchup because the creature removal is almost an afterthought. The Drogskol Captain hexproof lock is devastating in game 1, and since Bant Spirits is all about finding and engaging that lock, it can be very hard for Jund to interact. Hand disruption is therefore Jund's most important disruption.
- Total Control Wins: 25 (50%)
- Total Test Wins: 25 (50%)
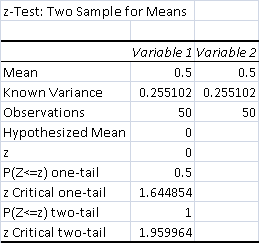
There was absolutely no difference between the test and control deck, so unsurprisingly the data isn't significant.
Fire doesn't alter Spirits chances of finding the lock naturally or via Collected Company, so it had the same odds as Bolt of being relevant. The maindeck Geists were key.
Humans
I expected Humans to be hit hard by Fire. It doesn't play any land interaction and most creatures have less than three toughness. Its saving graces are the disruption package, particularly Meddling Mage. However, Jund plays so many answers that it should be able to overwhelm Mage.
- Total Control Wins: 26 (52%)
- Total Test Wins: 32 (64%)
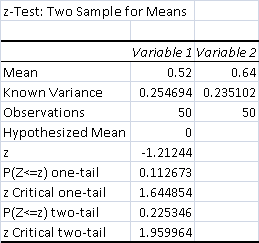
The data narrowly misses being weakly significant, at p > .1. Again, one fewer control win or another test win and it would have been weakly significant.
 I was not expecting this result. The assumption was that Fire combo decimates creature decks. The problem was that Jund had trouble assembling the combo reliably in time to crush Humans. Also, because of the aforementioned tension with removal spells, I couldn't just kill a turn one Noble Hierarch or Champion of the Parish every game. This let Humans start snowballing, and made games harder. When the combo did come together early, it was crushing. When not, Humans had the time it needed to be Humans, and the removal proved stretched too thin to keep up.
I was not expecting this result. The assumption was that Fire combo decimates creature decks. The problem was that Jund had trouble assembling the combo reliably in time to crush Humans. Also, because of the aforementioned tension with removal spells, I couldn't just kill a turn one Noble Hierarch or Champion of the Parish every game. This let Humans start snowballing, and made games harder. When the combo did come together early, it was crushing. When not, Humans had the time it needed to be Humans, and the removal proved stretched too thin to keep up.
Ironworks
Ironworks was capable of winning on turn three. It was also primarily made up of cantrips. Thus, Jund was never safe, no matter how much hand disruption it had. The only hope was to stick threats, race, and pray. Thanks to Engineered Explosives, Scavenging Ooze wasn't effective disruption. Post-board Surgical Extraction was decent, but not outstanding.
- Total Control Wins: 19 (38%)
- Total Test Wins: 18 (36%)
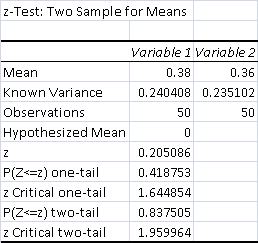
The data is not significant, which is unsurprising since the control and test are only one match apart.
Just as with Tron, Fire didn't do anything critical to the matchup, so it had no real effect.
A Wrinkle...
The matchup data shows that Punishing Fire did not have a meaningful effect on Jund's overall win percentage. Since it could not muster a significant result against Humans, the  matchup where it should have been most devastating, this would suggest that it is an unban candidate. The supposed machine-gun effect appears to be overblown.
matchup where it should have been most devastating, this would suggest that it is an unban candidate. The supposed machine-gun effect appears to be overblown.
However, that isn't the whole story. This was the most miserable test I've ever run. There are a number of gameplay and intangible reasons that I'll get to next week, but they pale in comparison to this test taking longer than any other. I started testing in early November and didn't finish until March. This was not because I had to work around availability gaps. The individual games took measurably longer than ever before, and dragged the whole process out. This isn't entirely unexpected given experience from Legacy, but in Modern, it suggests that Fire is more similar to Sensei's Diving Top than to Splinter Twin or Chrome Mox.
...In Time
I stopped using MTGO for these tests when the chess clock altered results. A player timing out is not the same as him losing the game. I stopped timing the matches altogether when draws required rematches and lengthened the test. We play every game until its conclusion, and don't concede until the game is actually lost; being 0% to win isn't quite the same as actually losing. The former means that UW is up too many cards to plausibly fight through. The latter means they're upticking Jace, and you don't and will never have an answer. The exception is that as soon as combo decks demonstrate a deterministic loop, we concede.
 This meant that games dragged on because Jund was rarely actually out. It could always draw another Grove or Fire and work its way back in. It was also rare for the other deck to be out, since a single Fire and Grove aren't much on their own. As a result, the games with Firey Jund took longer than the control games. I suspected this would be the case during exploratory testing, and kept track of how long each match took.
This meant that games dragged on because Jund was rarely actually out. It could always draw another Grove or Fire and work its way back in. It was also rare for the other deck to be out, since a single Fire and Grove aren't much on their own. As a result, the games with Firey Jund took longer than the control games. I suspected this would be the case during exploratory testing, and kept track of how long each match took.
- Average Control Match Time: 27.28 minutes
- Average Test Match Time: 31.97 minutes
The test matches took roughly five minutes longer on average. This may not seem like much, but I want to emphasize that these are the average times, between widely different types of deck. As you can see in the result printout below, there was considerable fluctuation in the data.
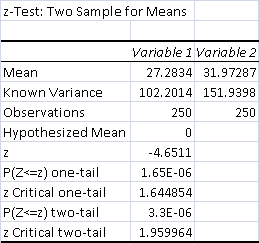
The p value of the time data is incredibly small, so it is strongly significant at the 99% level. As an explanation, when internal variance is very high, the threshold for significance drops.
UW Control
UW Control takes a while to win, and the matchup is incredibly grindy. Naturally, it takes a lot of time.
- Average Control Match Time: 31.17 minutes
- Average Test Match Time: 40.71 minutes
- Control Matches 50 minutes or longer: 2
- Test Matches 50 minutes or longer: 7
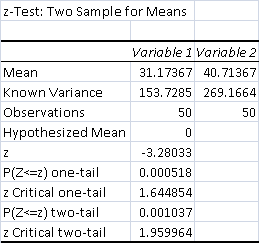
The data is significant at the 99% level, p < .01. Fire and Grove's inclusion did increase the length of the matchup by the observed amount.
Again, Jund was never out of game 1; so as long as it still had a Grove in-deck, it could win the game. That forced UW to try and race Jund, and maindeck UW's not good at racing. The longest match I played in the whole test was Test Match 38, a ~95 minute epic where the roughly hour-long game one was decided by UW decking itself. Jund actually lost that match, because games 2-3 UW slammed down and protected Geist on turn three.
Mono-Green Tron
Tron games are generally fast, since Tron's trying to do its thing turn three every game. If it does, the game is almost always over shortly afterward. If it doesn't, the game still needs to end quickly, or Tron will find what it was missing.
- Average Control Match Time: 23.78 minutes
- Average Test Match Time: 26.05 minutes
- Control Matches 50 minutes or longer: 0
- Test Matches 50 minutes or longer: 0
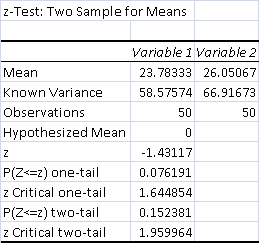
The data is weakly significant, at p < .01. The result is not conclusive, but also cannot be discounted. The time that Jund spends durdling with Grove and Fire seems to add up even in matches where it's not a priority.
Bant Spirits
Spirits games are ones of extremes. Either Spirits quickly locks Jund out, Jund guts Spirits's hand and then board, or we see a prolonged grindfest were the last threat wins.
- Average Control Match Time: 27.04 minutes
- Average Test Match Time: 30.98 minutes
- Control Matches 50 minutes or longer: 1
- Test Matches 50 minutes or longer: 2
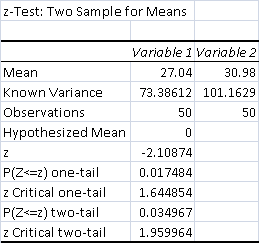
The data is strongly significant, at p < .05. It is very close to 99%, but that's gravey compared to being 95% confidant. Normally, Jund runs out of removal before Spirits runs out of creatures. However, that couldn't happen game one, so the grinding stretched on and on.
Humans
Humans is naturally a fast deck. Jund is seeking to string out the match. This typically means that Humans' wins are very fast, while Jund's take a long time.
- Average Control Match Time: 25.4 minutes
- Average Test Match Time: 29.92 minutes
- Control Matches 50 minutes or longer: 0
- Test Matches 50 minutes or longer: 1
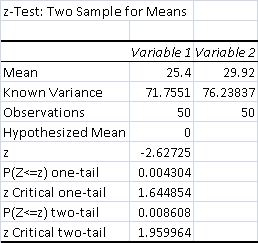
The data is strongly significant, at p < .01. This test yielded a lot of 99% confidence intervals. The tendency of Jund's wins to take longer got worse. This was exacerbated by Grove's life prolonging a number of normal games and costing Jund several races.
Ironworks
Ironworks was the most extreme individual match. Ironworks is capable of demonstrating an unbreakable loop on turn three, but actually getting to that point can take awhile. This matchup had the second most matches go past normal round time and the two shortest matches. The shortest two were eight-minute stompings, one win for control Jund and one loss for Firey Jund, both times after the loser mulliganed to oblivion both games.
- Average Control Match Time: 29.02 minutes
- Average Test Match Time: 32.2 minutes
- Control Matches 50 minutes or longer: 2
- Test Matches 50 minutes or longer: 5
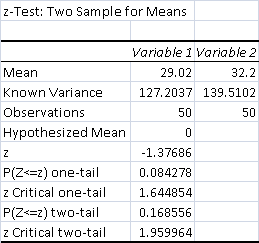
The data is weakly significant, at p < 0.1.
In fairness to Fire, not all the increase in long matches was its fault. Sometimes, Ironworks can't assemble an actual loop, and has to burn through its deck like Eggs to win.
 Whole Story
Whole Story
The end result of my data collection is that there's no evidence that Punishing Fire would boost Jund to dangerous levels. It didn't impact any matchup in a significant way. However, it did have a strongly significant impact on match length, giving it implications for tournament logistics. This means there's a lot more to Fire than meets the eye, and power alone isn't sufficient in discussing whether it is an unban consideration. The intangibles are critical in assessing the card. Join me next week for those qualitative results and my conclusions from this test.

Hey. Thanks for the analysis. FYI, there are a few times when you wrote p ) that I think you meant p < 0.1 (particularly in the first part of your article)
Although this was an excellent read, as always, I had a statistical question. Why did you decide to do a z-test on your means instead of a t-test? I cannot possibly believe that you have the true/population standard deviation of both control and Punishing Jund’s win-rate (and I would be surprised if you had even one’s) and as such your z-test would yield inaccurate results. I know that this is a relatively informal project for which extreme precision is not necessarily paramount, but seeing as you took the time to carefully explain p-values I would think this sort of thing is important to you. Thanks in advance for any reply you offer.
A distinction, I report a z-test. I do a number of statistical tests once the data’s in, including t-tests, and use a number of data analysis tools to deal with the variance/sdev problems. To some extent I don’t have to know the “true” deviation because it’s a controlled experiment with a hypothesis test, but I am aware of the statistical issues so I try and confirm my test results.
Most people have very limited experience with statistics and the z-test is usually the one they actually know or at least vaguely remember from their one semester in high school. It makes sense to use the one that readers are most likely familiar with, regardless of what I actually do.
I’ve also never had a situation where switching tests yielded divergent results (i.e. significant became non-significant). Instead it’s been differences in magnitude like p=.04854 instead of p=.049, so it makes no practical difference.
In the beginning, I had some trouble where the t-test gave weird results because the data set was binary. The z-tests didn’t care so I used them exclusively, but I’ve since learned how to fix that programming error so these days it’s all about ease of understanding.
This is the insanely high quality content that Modern Nexus has come to be known for.
Would you agree an unban would be Thopter/Sword 2.0? Hope we don’t see it too much but basically irrelevant to the format now, safe to release as a extra tool for one tier 4 brew?
Or is your distaste for the card sufficient to make you think it’s not worth the risk ? (I felt this way about bitterblossom)
I’ll be going into detail in the next article, but in short: the risk is very high and the reward very low. In the right, super grindy shell Fire will be very good. Even if the deck itself is just A Deck in Modern, such a deck would just eat into tournament time. This means that it might not be oppressive to the metagame but to tournament Magic, and that’s a pretty good reason to keep it banned.